Probability distributions, random variables¶
Dr. Tirthajyoti Sarkar, Fremont, CA 94536¶
This notebook illustrates the following concepts using simple scripts and functions from Scipy and Numpy packages.
- Random variables
- Law of the large number
- Expected value
- Discrete probability distributions
- Concitinuous probability distributions
- Moments, variance, and other properties of probability distributions
import random
import numpy as np
import matplotlib.pyplot as plt
Throwing dice many times (illustrating the Law of large numbers)¶
When we throw dice a large number of times, the average reaches 3.5 which is the expected value.
dice = [x for x in range(1,7)]
print("A fair dice has 6 faces:",dice)
def throw_dice(n=10):
"""
Throw a (fair) die n number of times and returns the result in an array
"""
r = []
for _ in range(n):
r.append(random.choice(dice))
return np.array(r)
throw_dice(1)
throw_dice(6)
for i in [1,5,10,50,100,500,1000,5000,10000]:
print("Average of {} dice throws: {}".format(i,round(throw_dice(i).mean(),2)))
Expected value of a continuous function¶
Expected value or mean: the weighted average of the possible values, using their probabilities as their weights; or the continuous analog thereof.
Let $X$ be a random variable with a finite number of finite outcomes $x_1$,$x_2$,$x_3$,... occurring with probabilities $p_1$,$p_2$,$p_3$,... respectively. The expectation of $X$ is, then, defined as
$$ E[X]=\sum_{i=1}^{k}x_{i}\,p_{i}=x_{1}p_{1}+x_{2}p_{2}+\cdots +x_{k}p_{k} $$Since, all the probabilities $p_1$, $p_2$, $p_3$, add up to 1, $p_1+p_2+p_3+...=1$, it is the weighted average.
For, continuous probability distributions, with a density function (PDF) of $f(x)$, the expected value is given by,
$$ {\displaystyle \operatorname {E} [X]=\int _{\mathbb {R} }xf(x)\,dx.}$$Let's calculate the expected value of the function $P(x)=x.e^{-x}$ between $x=0$ and $x=\infty$¶
We are trying to compute, $$ \int _{0}^{\infty}x.P(x).dx = \int _{0}^{\infty}x.[x.e^{-x}].dx = \int _{0}^{\infty}x^2.e^{-x}.dx$$
def func(x):
import numpy as np
return x*np.exp(-x)
x = np.arange(0,10,0.1)
y = func(x)
plt.plot(x,y,color='k',lw=3)
plt.title("Function of $x.e^{-x}$",fontsize=15)
plt.grid(True)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()

Use scipy.integrate module¶
We will increase the upper limit of the integral slowly and show that the integral does not change much after a while.
import scipy.integrate
integral_value=[]
for i in range(1,11):
integral=scipy.integrate.quad(func,0,i)[0]
integral_value.append(integral)
print("The integral value for upper limit of {} is : {}".format(i,integral))
plt.plot(range(1,11),integral_value,color='k',lw=3)
plt.title("Integral of $x.e^{-x}$",fontsize=15)
plt.grid(True)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()

def expectation(x):
return x*func(x)
x = np.arange(0,20,0.1)
y = expectation(x)
plt.plot(x,y,color='k',lw=3)
plt.title("Function of $x^2.e^{-x}$",fontsize=15)
plt.grid(True)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()

integral_value=[]
for i in range(1,11):
integral=scipy.integrate.quad(expectation,0,i)[0]
integral_value.append(integral)
print("The integral value for upper limit of {} is : {}".format(i,integral))
plt.plot(range(1,11),integral_value,color='k',lw=3)
plt.title("Integral of $x^2.e^{-x}$",fontsize=15)
plt.grid(True)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()

Discrete and Continuous Distributions¶
Probability distributions are generally divided into two classes. A discrete probability distribution (applicable to the scenarios where the set of possible outcomes is discrete, such as a coin toss or a roll of dice) can be encoded by a discrete list of the probabilities of the outcomes, known as a probability mass function.
On the other hand, a continuous probability distribution (applicable to the scenarios where the set of possible outcomes can take on values in a continuous range (e.g. real numbers), such as the temperature on a given day) is typically described by probability density functions (with the probability of any individual outcome actually being 0). Such distributions are generally described with the help of probability density functions.
Some Essential Terminologies¶
- Mode: for a discrete random variable, the value with highest probability (the location at which the probability mass function has its peak); for a continuous random variable, a location at which the probability density function has a local peak.
- Support: the smallest closed set whose complement has probability zero.
- Head: the range of values where the pmf or pdf is relatively high.
- Tail: the complement of the head within the support; the large set of values where the pmf or pdf is relatively low.
- Expected value or mean: the weighted average of the possible values, using their probabilities as their weights; or the continuous analog thereof.
- Median: the value such that the set of values less than the median, and the set greater than the median, each have probabilities no greater than one-half.
- Variance: the second moment of the pmf or pdf about the mean; an important measure of the dispersion of the distribution.
Standard deviation: the square root of the variance, and hence another measure of dispersion.
Symmetry: a property of some distributions in which the portion of the distribution to the left of a specific value is a mirror image of the portion to its right.
- Skewness: a measure of the extent to which a pmf or pdf "leans" to one side of its mean. The third standardized moment of the distribution.
- Kurtosis: a measure of the "fatness" of the tails of a pmf or pdf. The fourth standardized moment of the distribution.
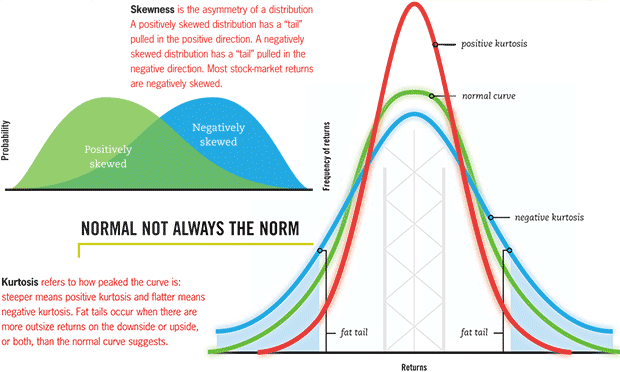
Quick mathematical definitions of mean, variance, skewness, and kurtosis with respect to a PDF $P(x)$¶
$$\text{1st raw moment } \mathbf{Mean\ (1st\ moment):} \int x.P(x).dx$$$$\text{Centralized 2nd moment } \mathbf{Variance\ (2nd\ moment):} \int (x-\mu)^2.P(x).dx$$$$\text{Pearson's 3rd moment (Standardized) }\mathbf{Skew\ (3rd\ moment):} \int\left ( \frac{x-\mu}{\sigma} \right )^3.P(x).dx$$$$\text{Pearson's 4th moment (Standardized) }\mathbf{Kurtosis\ (4th\ moment):} \int\left ( \frac{x-\mu}{\sigma} \right )^4.P(x).dx$$Bernoulii distribution¶
The Bernoulli distribution, named after Swiss mathematician Jacob Bernoulli, is the probability distribution of a random variable which takes the value 1 with probability $p$ and the value 0 with probability $q = 1 − p$ — i.e., the probability distribution of any single experiment that asks a yes–no question; the question results in a boolean-valued outcome, a single bit of information whose value is success/yes/true/one with probability $p$ and failure/no/false/zero with probability $q$.
It can be used to represent a coin toss where 1 and 0 would represent "head" and "tail" (or vice versa), respectively. In particular, unfair coins would have $p ≠ 0.5$.

The probability mass function $f$ of this distribution, over possible outcomes $k$, is
$${\displaystyle f(k;p)={\begin{cases}p&{\text{if }}k=1,\\[6pt]1-p&{\text{if }}k=0.\end{cases}}}$$from scipy.stats import bernoulli
Generate random variates¶
# p=0.5 i.e. fair coin
bernoulli.rvs(p=0.5,size=10)
Loaded coin towards tail, p=0.2 for head¶
# p=0.2 i.e. more tails (0) than heads(1)
bernoulli.rvs(p=0.2,size=20)
Loaded coin towards head, p=0.8 for head¶
# p=0.8 i.e. more heads (1) than tails (0)
bernoulli.rvs(p=0.8,size=20)
Note, a single run or even a small number of runs may not produce the expected distribution of 1's and 0's.¶
For example, if you assign $p=0.5$, you may not get half 1's and half 0's every time you evaluate the function. Experiment with $N$ number of trials to see how the probability distribution gradually centers around 0.5.
N_trials = [10,20,50,100,200,500,1000,2000,5000] # Number of trials
pr=0.5 # Fair coin toss probability
av = [] # Empty list to store the average of the random variates
# Generate 10 variates every time and take the average. That should be # of 1's i.e. 0.5 for a fair coin.
for i in N_trials:
for n in range(1,i+1):
av.append(np.mean(bernoulli.rvs(p=pr,size=10)))
if (i==10):
plt.title("Distribution with {} trials of 10 coin tosses".format(i))
plt.hist(av,bins=10,edgecolor='k',color='orange')
plt.xlim(0.0,1.0)
plt.xticks([0.1*i for i in range(11)])
plt.grid(True)
plt.show()
else:
plt.title("Distribution with {} trials of 10 coin tosses".format(i))
plt.hist(av,bins=25,edgecolor='k',color='orange')
plt.xlim(0.0,1.0)
plt.xticks([0.1*i for i in range(11)])
plt.grid(True)
plt.show()









Mean, variance, skew, and kurtosis¶
Use bernoulli.stats() method
print("A fair coin is spinning...\n"+"-"*30)
pr=0.5 # Fair coin toss probability
mean, var, skew, kurt = bernoulli.stats(p=pr, moments='mvsk')
print("Mean:",mean)
print("Variance:",var)
print("Skew:",skew)
print("Kurtosis:",kurt)
print("\nNow a biased coin is spinning...\n"+"-"*35)
pr=0.7 # Biased coin toss probability
mean, var, skew, kurt = bernoulli.stats(p=pr, moments='mvsk')
print("Mean:",mean)
print("Variance:",var)
print("Skew:",skew)
print("Kurtosis:",kurt)
Probability mass function (PMF) and cumulative distribution function (CDF)¶
rv = bernoulli(0.6)
x=0
print("Probability mass function for {}: {}".format(x,rv.pmf(x)))
x=0.5
print("Probability mass function for {}: {}".format(x,rv.pmf(x)))
x=1.0
print("Probability mass function for {}: {}".format(x,rv.pmf(x)))
x=1.2
print("Probability mass function for {}: {}".format(x,rv.pmf(x)))
print("CDF for x < 0:",rv.cdf(-2))
print("CDF for 0< x <1:",rv.cdf(0.75))
print("CDF for x >1:",rv.cdf(2))
Binomial distribution¶
The binomial distribution with parameters $n$ and $p$ is the discrete probability distribution of the number of successes in a sequence of $n$ independent experiments, each asking a yes–no question, and each with its own boolean-valued outcome: a random variable containing single bit of information: success/yes/true/one (with probability $p$) or failure/no/false/zero (with probability $q = 1 − p$). A single success/failure experiment is also called a Bernoulli trial or Bernoulli experiment and a sequence of outcomes is called a Bernoulli process.
For a single trial, i.e., n = 1, the binomial distribution is a Bernoulli distribution. The binomial distribution is the basis for the popular binomial test of statistical significance.
The binomial distribution is frequently used to model the number of successes in a sample of size n drawn with replacement from a population of size N. If the sampling is carried out without replacement, the draws are not independent and so the resulting distribution is a hypergeometric distribution, not a binomial one. However, for N much larger than n, the binomial distribution remains a good approximation, and is widely used.
In general, if the random variable $X$ follows the binomial distribution with parameters n ∈ ℕ and p ∈ [0,1], we write X ~ B(n, p). The probability of getting exactly $k$ successes in $n$ trials is given by the probability mass function:
$${\Pr(k;n,p)=\Pr(X=k)={n \choose k}p^{k}(1-p)^{n-k}}$$for k = 0, 1, 2, ..., n, where
$${\displaystyle {\binom {n}{k}}={\frac {n!}{k!(n-k)!}}}$$
Generate random variates¶
8 coins are flipped (or 1 coin is flipped 8 times), each with probability of success (1) of 0.25. This trial/experiment is repeated for 10 times.
from scipy.stats import binom
k=binom.rvs(8,0.25,size=10)
print("Number of success for each trial:",k)
print("Average of the success:", np.mean(k))
Mean, variance, skew, and kurtosis¶
$$\textbf{Mean} = n.p,\ \textbf{Variance}= n.p(1 - p), \textbf{skewness}= \frac{1-2p}{\sqrt{n.p(1-p)}}, \ \textbf{kurtosis}= \frac{1-6p(1-p)}{n.p(1-p)}$$Use binom.stats() method
print("A fair coin (p=0.5) is spinning 5 times\n"+"-"*35)
pr=0.5 # Fair coin toss probability
n=5
mean, var, skew, kurt = binom.stats(n=n,p=pr, moments='mvsk')
print("Mean:",mean)
print("Variance:",var)
print("Skew:",skew)
print("Kurtosis:",kurt)
print("\nNow a biased coin (p=0.7) is spinning 5 times...\n"+"-"*45)
pr=0.7 # Biased coin toss probability
n=5
mean, var, skew, kurt = binom.stats(n=n,p=pr, moments='mvsk')
print("Mean:",mean)
print("Variance:",var)
print("Skew:",skew)
print("Kurtosis:",kurt)
Visualizing probability mass function (PMF)¶
n=40
pr=0.5
rv = binom(n,pr)
x=np.arange(0,41,1)
pmf1 = rv.pmf(x)
n=40
pr=0.15
rv = binom(n,pr)
x=np.arange(0,41,1)
pmf2 = rv.pmf(x)
n=50
pr=0.6
rv = binom(n,pr)
x=np.arange(0,41,1)
pmf3 = rv.pmf(x)
plt.figure(figsize=(12,6))
plt.title("Probability mass function: $\\binom{n}{k}\, p^k (1-p)^{n-k}$\n",fontsize=20)
plt.scatter(x,pmf1)
plt.scatter(x,pmf2)
plt.scatter(x,pmf3,c='k')
plt.legend(["$n=40, p=0.5$","$n=40, p=0.3$","$n=50, p=0.6$"],fontsize=15)
plt.xlabel("Number of successful trials ($k$)",fontsize=15)
plt.ylabel("Probability of success",fontsize=15)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.grid(True)
plt.show()

Visualize the cumulative distrubition function (cdf)¶
Cumulative distribution function for binomial distribution can also be represented in terms of the regularized incomplete beta function, as follows
$${\displaystyle {\begin{aligned}F(k;n,p)&=\Pr(X\leq k)\\&=I_{1-p}(n-k,k+1)\\&=(n-k){n \choose k}\int _{0}^{1-p}t^{n-k-1}(1-t)^{k}\,dt.\end{aligned}}}$$n=40
pr=0.5
rv = binom(n,pr)
x=np.arange(0,41,1)
cdf1 = rv.cdf(x)
n=40
pr=0.3
rv = binom(n,pr)
x=np.arange(0,41,1)
cdf2 = rv.cdf(x)
n=50
pr=0.6
rv = binom(n,pr)
x=np.arange(0,41,1)
cdf3 = rv.cdf(x)
plt.figure(figsize=(12,6))
plt.title("Cumulative distribution function: $I_{1-p}(n - k, 1 + k)$\n",fontsize=20)
plt.scatter(x,cdf1)
plt.scatter(x,cdf2)
plt.scatter(x,cdf3,c='k')
plt.legend(["$n=40, p=0.5$","$n=40, p=0.3$","$n=50, p=0.6$"],fontsize=15)
plt.xlabel("Number of successful trials",fontsize=15)
plt.ylabel("Cumulative probability of success",fontsize=15)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.grid(True)
plt.show()

Interval that contains a specific percentage of distribution¶
Use binom.interval method
n=40
pr=0.3
percent=25
interval = binom.interval(percent/100,n,pr,loc=0)
print("Interval that contains {} percent of distribution with an experiment with {} trials and {} success probability is: {}"
.format(percent,n,pr,interval))
Poisson Distribution¶
The Poisson distribution (named after French mathematician Siméon Denis Poisson), is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time or space if these events occur with a known constant rate and independently of the time since the last event. The Poisson distribution can also be used for the number of events in other specified intervals such as distance, area or volume.
For instance, an individual keeping track of the amount of mail they receive each day may notice that they receive an average number of 4 letters per day. If receiving any particular piece of mail does not affect the arrival times of future pieces of mail, i.e., if pieces of mail from a wide range of sources arrive independently of one another, then a reasonable assumption is that the number of pieces of mail received in a day obeys a Poisson distribution. Other examples, that may follow a Poisson distribution, include
- number of phone calls received by a call center per hour
- number of decay events per second from a radioactive source
- The number of meteors greater than 1 meter diameter that strike Earth in a year
- The number of patients arriving in an emergency room between 10 and 11 pm
Poisson distribution is a limiting case of a Binomial Distribution where the number of trials is sufficiently bigger than the number of successes one is asking about i.e. $n>>1>>p$
An event can occur 0, 1, 2, … times in an interval. The average number of events in an interval is designated $\lambda$. This is the event rate, also called the rate parameter. The probability of observing k events in an interval is given by the equation
${P(k{\text{ events in interval}})=e^{-\lambda }{\frac {\lambda ^{k}}{k!}}}$
where,
${\lambda}$ is the average number of events per interval
e is the number 2.71828... (Euler's number) the base of the natural logarithms
k takes values 0, 1, 2, … k! = k × (k − 1) × (k − 2) × … × 2 × 1 is the factorial of k.
from scipy.stats import poisson
la=0.5
rv = poisson(la)
x=np.arange(0,11,1)
pmf1 = rv.pmf(x)
la=1
rv = poisson(la)
x=np.arange(0,11,1)
pmf2 = rv.pmf(x)
la=5
rv = poisson(la)
x=np.arange(0,11,1)
pmf3 = rv.pmf(x)
plt.figure(figsize=(9,6))
plt.title("Probability mass function: $e^{-\lambda}{(\lambda^k/k!)}$\n",fontsize=20)
plt.scatter(x,pmf1,s=100)
plt.scatter(x,pmf2,s=100)
plt.scatter(x,pmf3,c='k',s=100)
plt.legend(["$\lambda=0.5$","$\lambda=1$","$\lambda=5$"],fontsize=15)
plt.xlabel("Number of occurences ($k$)",fontsize=15)
plt.ylabel("$Pr(X=k)$",fontsize=15)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.grid(True)
plt.show()

Visualizing the cumulative distribution function¶
la=0.5
rv = poisson(la)
x=np.arange(0,11,1)
cdf1 = rv.cdf(x)
la=2
rv = poisson(la)
x=np.arange(0,11,1)
cdf2 = rv.cdf(x)
la=5
rv = poisson(la)
x=np.arange(0,11,1)
cdf3 = rv.cdf(x)
plt.figure(figsize=(9,6))
plt.title("Cumulative distribution function\n",fontsize=20)
plt.scatter(x,cdf1,s=100)
plt.scatter(x,cdf2,s=100)
plt.scatter(x,cdf3,c='k',s=100)
plt.legend(["$\lambda=0.5$","$\lambda=2$","$\lambda=5$"],fontsize=15)
plt.xlabel("Number of occurences ($k$)",fontsize=15)
plt.ylabel("Cumulative distribution function",fontsize=15)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.grid(True)
plt.show()

Moments - mean, variance, skew, and kurtosis¶
Various moments of a Poisson distributed random variable $X$ are as follows:
$$ \textbf{Mean}=\lambda,\ \textbf{Variance}=\lambda,\ \textbf{skewness}=\frac {1}{\sqrt{\lambda}},\ \textbf{kurtosis}=\frac{1}{\lambda}$$Geometric distribution¶
The geometric distribution is either of two discrete probability distributions:
- The probability distribution of the number X of Bernoulli trials needed to get one success, supported on the set { 1, 2, 3, ...}
- The probability distribution of the number Y = X − 1 of failures before the first success, supported on the set { 0, 1, 2, 3, ... }
Which of these one calls "the" geometric distribution is a matter of convention and convenience.
These two different geometric distributions should not be confused with each other. Often, the name shifted geometric distribution is adopted for the former one (distribution of the number $X$); however, to avoid ambiguity, it is considered wise to indicate which is intended, by mentioning the support explicitly.
The geometric distribution gives the probability that the first occurrence of success requires $k$ independent trials, each with success probability $p$. If the probability of success on each trial is $p$, then the probability that the $k^{th}$ trial (out of $k$ trials) is the first success is
${\Pr(X=k)=(1-p)^{k-1}\,p\,}$
for $k = 1, 2, 3, ....$
The above form of the geometric distribution is used for modeling the number of trials up to and including the first success. By contrast, the following form of the geometric distribution is used for modeling the number of failures until the first success:
${\Pr(Y=k)=(1-p)^{k}\,p\,}$
for $k = 0, 1, 2, 3, ....$
In either case, the sequence of probabilities is a geometric sequence.
The geometric distribution is an appropriate model if the following assumptions are true.
- The phenomenon being modelled is a sequence of independent trials.
- There are only two possible outcomes for each trial, often designated success or failure.
- The probability of success, p, is the same for every trial.
from scipy.stats import geom
Generate random variates¶
It is difficult to get a success with low probability, so it takes more trials
r=geom.rvs(p=0.1,size=10)
print(r)
It is easier to get the first success with higher probability, so it takes less number of trials
r=geom.rvs(p=0.5,size=10)
print(r)
Visualizing probability mass function (PMF)¶
p=0.1
rv = geom(p)
x=np.arange(1,11,1)
pmf1 = rv.pmf(x)
p=0.25
rv = geom(p)
x=np.arange(1,11,1)
pmf2 = rv.pmf(x)
p=0.75
rv = geom(p)
x=np.arange(1,11,1)
pmf3 = rv.pmf(x)
plt.figure(figsize=(9,6))
plt.title("Probability mass function: $(1-p)^{k-1}p$\n",fontsize=20)
plt.scatter(x,pmf1,s=100)
plt.scatter(x,pmf2,s=100)
plt.scatter(x,pmf3,c='k',s=100)
plt.plot(x,pmf1)
plt.plot(x,pmf2)
plt.plot(x,pmf3,c='k')
plt.legend(["$p=0.1$","$p=0.25$","$p=0.75$"],fontsize=15)
plt.xlabel("Number of trials till first success ($k$)",fontsize=15)
plt.ylabel("$Pr(X=x)$",fontsize=15)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.grid(True)
plt.show()

Visualizing cumulative distribution function¶
p=0.1
rv = geom(p)
x=np.arange(1,11,1)
cdf1 = rv.cdf(x)
p=0.25
rv = geom(p)
x=np.arange(1,11,1)
cdf2 = rv.cdf(x)
p=0.75
rv = geom(p)
x=np.arange(1,11,1)
cdf3 = rv.cdf(x)
plt.figure(figsize=(9,6))
plt.title("Cumulative distribution function: $1-(1-p)^k$\n",fontsize=20)
plt.scatter(x,cdf1,s=100)
plt.scatter(x,cdf2,s=100)
plt.scatter(x,cdf3,c='k',s=100)
plt.plot(x,cdf1)
plt.plot(x,cdf2)
plt.plot(x,cdf3,c='k')
plt.legend(["$p=0.1$","$p=0.25$","$p=0.75$"],fontsize=15)
plt.xlabel("Number of trials till first success ($k$)",fontsize=15)
plt.ylabel("$Pr(X\leq x)$",fontsize=15)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.grid(True)
plt.show()

Expected value (mean), variance, skewness, kurtosis¶
Various moments of a geometrically distributed random variable $X$ are as follows:
$$ \textbf{Mean}=\frac {1}{p},\ \textbf{Variance}=\frac {1-p}{p^2},\ \textbf{skewness}=\frac {2-p}{\sqrt{1-p}},\ \textbf{kurtosis}=6+\frac{p^2}{1-p}$$Uniform (continuous) distribution¶
This is the distribution of the likelihood of uniformly randomly selecting an item out of a finite collection.
We are mostly familiar with the discontinuous version of this distribution. For example, in case of throwing a fair dice, the probability distribution of a single throw is given by:
$$ \left \{ \frac{1}{6},\ \frac{1}{6}, \ \frac{1}{6},\ \frac{1}{6},\ \frac{1}{6},\ \frac{1}{6} \right \} $$
For the continuous case, the PDF looks deceptively simple, but the concept is subtle,
$$ f(x)={\begin{cases}{\frac {1}{b-a}}&\mathrm {for} \ a\leq x\leq b,\\[8pt]0&\mathrm {for} \ x<a\ \mathrm {or} \ x>b\end{cases}} $$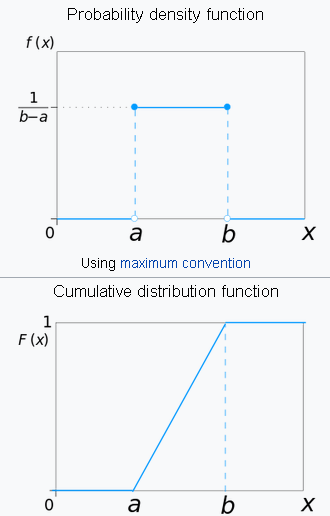
from scipy.stats import uniform
Generate random variates (default between 0 and 1)¶
uniform.rvs(size=5)
Change the loc and scale parameters to move the range¶
# Random floats between -10 and 0
uniform.rvs(loc=-10,scale=10,size=5)
# Random floats between -10 and +10
uniform.rvs(loc=-10,scale=20,size=5)
Normal (Gaussian) distribution¶
In probability theory, the normal (or Gaussian or Gauss or Laplace–Gauss) distribution is a very common continuous probability distribution. Normal distributions are important in statistics and are often used in the natural and social sciences to represent real-valued random variables whose distributions are not known. A random variable with a Gaussian distribution is said to be normally distributed and is called a normal deviate.
The normal distribution is useful because of the central limit theorem. In its most general form, under some conditions (which include finite variance), it states that averages of samples of observations of random variables independently drawn from independent distributions converge in distribution to the normal, that is, they become normally distributed when the number of observations is sufficiently large.
Physical quantities that are expected to be the sum of many independent processes (such as measurement errors) often have distributions that are nearly normal. Moreover, many results and methods (such as propagation of uncertainty and least squares parameter fitting) can be derived analytically in explicit form when the relevant variables are normally distributed.
PDF and CDF¶
The probability density function (PDF) is given by, $$ f(x\mid \mu ,\sigma ^{2})={\frac {1}{\sqrt {2\pi \sigma ^{2}}}}e^{-{\frac {(x-\mu )^{2}}{2\sigma ^{2}}}} $$ where,
- $\mu$ is the mean or expectation of the distribution (and also its median and mode),
- $\sigma$ is the standard deviation, and $\sigma^2$ is the variance.
Cumulative distribution function (CDF) is given by, $$\frac{1}{2}\left [ 1+\text{erf} \left ( \frac{x-\mu}{\sigma\sqrt{2}}\right ) \right ]$$
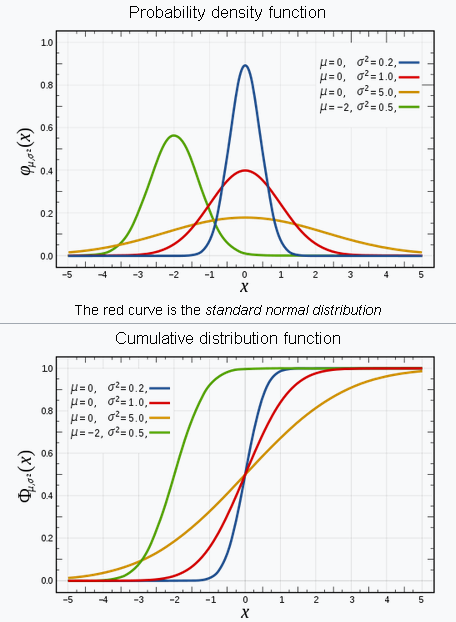
Scipy Stats page: https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.norm.html#scipy.stats.norm
from scipy.stats import norm
x = np.linspace(-3, 3, num = 100)
constant = 1.0 / np.sqrt(2*np.pi)
pdf_normal_distribution = constant * np.exp((-x**2) / 2.0)
fig, ax = plt.subplots(figsize=(10, 5));
ax.plot(x, pdf_normal_distribution);
ax.set_ylim(0);
ax.set_title('Normal Distribution', size = 20);
ax.set_ylabel('Probability Density', size = 20)

Derive the familiar 68-95-99.7 rule from the basic definition¶
def normalProbabilityDensity(x):
constant = 1.0 / np.sqrt(2*np.pi)
return(constant * np.exp((-x**2) / 2.0) )# Integrate PDF from -1 to 1
def integrate_normal(num_sigma):
result, _ = scipy.integrate.quad(normalProbabilityDensity, -num_sigma, num_sigma, limit = 1000)
return round(result,3)
print("The percentage of data present within 1 standard deviation:",integrate_normal(1))
print("The percentage of data present within 2 standard deviations:",integrate_normal(2))
print("The percentage of data present within 3 standard deviations:",integrate_normal(3))
Random variable generation using Numpy.random module¶
Numpy offers an amazing module called Numpy.random, which has all the important probability distributions built-in for generation. We will check it out for,
- Normal
- Uniform
- Binomial
- Chi-square
- Poisson
- F-distribution and Student's t-distribution
Generate normally distributed numbers with various mean and std.dev¶
In numpy.random.normal method, the loc argument is the mean, adnd the scale argument is the std.dev
a1 = np.random.normal(loc=0,scale=np.sqrt(0.2),size=100000)
a2 = np.random.normal(loc=0,scale=1.0,size=100000)
a3 = np.random.normal(loc=0,scale=np.sqrt(5),size=100000)
a4 = np.random.normal(loc=-2,scale=np.sqrt(0.5),size=100000)
plt.figure(figsize=(8,5))
plt.hist(a1,density=True,bins=100,color='blue',alpha=0.5)
plt.hist(a2,density=True,bins=100,color='red',alpha=0.5)
plt.hist(a3,density=True,bins=100,color='orange',alpha=0.5)
plt.hist(a4,density=True,bins=100,color='green',alpha=0.5)
plt.xlim(-7,7)
plt.show()

Generate dice throws and average them to show the emergence of Normality as per the Central Limit Theorem¶
We can use either np.random.uniform or np.random.randint to generate dice throws uniformly randomly
np.random.uniform(low=1.0,high=7.0,size=10)
def dice_throws(num_sample):
int_throws = np.vectorize(int)
throws = int_throws(np.random.uniform(low=1.0,high=7.0,size=num_sample))
return throws
dice_throws(5)
np.random.randint(1,7,5)
def average_throws(num_throws=5,num_experiment=100):
averages = []
for i in range(num_experiment):
a = dice_throws(num_throws)
av = a.mean()
averages.append(av)
return np.array(averages)
for i in [50,100,500,1000,5000,10000,50000,100000]:
plt.hist(average_throws(num_throws=20,num_experiment=i),bins=25,edgecolor='k',color='orange')
plt.title(f"Averaging with 20 throws and repeating it for {i} times")
plt.show()








Chi-square ($\chi^2$) distribution as a sum of squared Normally distributed variables¶
In probability theory and statistics, the chi-square distribution (also chi-squared or χ2-distribution) with k degrees of freedom is the distribution of a sum of the squares of k independent standard normal random variables.
The chi-square distribution is a special case of the gamma distribution and is one of the most widely used probability distributions in inferential statistics, notably in hypothesis testing or in construction of confidence intervals.
The probability density function (pdf) of the chi-square distribution is
$$ f(x;\,k)={\begin{cases}{\dfrac {x^{{\frac {k}{2}}-1}e^{-{\frac {x}{2}}}}{2^{\frac {k}{2}}\Gamma \left({\frac {k}{2}}\right)}},&x>0;\\0,&{\text{otherwise}}.\end{cases}} $$where $\Gamma({k/2})$ denotes the gamma function, which has closed-form values for integer $k$.
np.random.chisquare(df=3,size=10)
def sum_normal(k,num_experiments=100):
dist = []
for i in range(num_experiments):
total = 0
for i in range(k):
total+=(float(np.random.normal()))**2
dist.append(total)
return np.array(dist)
a1 = np.random.chisquare(df=5,size=1000)
plt.hist(a1,bins=25,edgecolor='k',color='orange')
plt.show()

a2 = sum_normal(k=5,num_experiments=1000)
plt.hist(a2,bins=25,edgecolor='k',color='orange')
plt.show()

F-distribution as a ratio of two scaled Chi-squared distributions¶
In probability theory and statistics, the F-distribution, also known as Snedecor's F distribution or the Fisher–Snedecor distribution (after Ronald Fisher and George W. Snedecor) is a continuous probability distribution that arises frequently as the null distribution of a test statistic, most notably in the analysis of variance (ANOVA), e.g., F-test.
Then the probability density function (pdf) for X is given by
$$ {\begin{aligned}f(x;d_{1},d_{2})&={\frac {\sqrt {\frac {(d_{1}\,x)^{d_{1}}\,\,d_{2}^{d_{2}}}{(d_{1}\,x+d_{2})^{d_{1}+d_{2}}}}}{x\,\mathrm {B} \!\left({\frac {d_{1}}{2}},{\frac {d_{2}}{2}}\right)}}\\&={\frac {1}{\mathrm {B} \!\left({\frac {d_{1}}{2}},{\frac {d_{2}}{2}}\right)}}\left({\frac {d_{1}}{d_{2}}}\right)^{\frac {d_{1}}{2}}x^{{\frac {d_{1}}{2}}-1}\left(1+{\frac {d_{1}}{d_{2}}}\,x\right)^{-{\frac {d_{1}+d_{2}}{2}}}\end{aligned}} $$Here $\mathrm {B}$ is the beta function. In many applications, the parameters $d_1$ and $d_2$ are positive integers, but the distribution is well-defined for positive real values of these parameters.
np.random.f(dfnum=5,dfden=25,size=10)
a1 = np.random.f(dfnum=5,dfden=25,size=1000)
plt.hist(a1,bins=25,edgecolor='k',color='orange')
plt.show()

a2 = sum_normal(k=5,num_experiments=1000)
a3 = sum_normal(k=25,num_experiments=1000)
a4 = a2/a3
plt.hist(a4,bins=25,edgecolor='k',color='orange')
plt.show()

Student's t-distribution¶
In probability and statistics, Student's t-distribution (or simply the t-distribution) is any member of a family of continuous probability distributions that arises when estimating the mean of a normally distributed population in situations where the sample size is small and population standard deviation is unknown. It was developed by William Sealy Gosset under the pseudonym Student.
The t-distribution plays a role in a number of widely used statistical analyses, including Student's t-test for assessing the statistical significance of the difference between two sample means, the construction of confidence intervals for the difference between two population means, and in linear regression analysis. The Student's t-distribution also arises in the Bayesian analysis of data from a normal family.
Student's t-distribution has the probability density function given by, $$ f(t)={\frac {\Gamma ({\frac {\nu +1}{2}})}{{\sqrt {\nu \pi }}\,\Gamma ({\frac {\nu }{2}})}}\left(1+{\frac {t^{2}}{\nu }}\right)^{\!-{\frac {\nu +1}{2}},\!} $$
where $\nu$ is the number of degrees of freedom and $\Gamma$ is the gamma function.
a1=np.random.standard_t(10,size=10000)
plt.hist(a1,bins=50,edgecolor='k',color='orange',density=True)
plt.show()
