tirthajyoti.github.io
Design-of-experiment (DOE) matrix generator for engineering and statistics
![]()
Copyright Notice and Code repository
Copyright (c): 2018-2028, Dr. Tirthajyoti Sarkar, Sunnyvale, CA 94086
It uses a MIT License, so although I retain the copyright of this particular code, please feel free to exercise your rights of the free software by using and enhancing it.
Please get the codebase from here.
Table of Contents
Introduction
Design of Experiment (DOE) is an important activity for any scientist, engineer, or statistician planning to conduct experimental analysis. This exercise has become critical in this age of rapidly expanding field of data science and associated statistical modeling and machine learning. A well-planned DOE can give a researcher meaningful data set to act upon with optimal number of experiments preserving critical resources.
After all, aim of Data Science is essentially to conduct highest quality scientific investigation and modeling with real world data. And to do good science with data, one needs to collect it through carefully thought-out experiment to cover all corner cases and reduce any possible bias.
What is a scientific experiment?
In its simplest form, a scientific experiment aims at predicting the outcome by introducing a change of the preconditions, which is represented by one or more independent variables, also referred to as “input variables” or “predictor variables.” The change in one or more independent variables is generally hypothesized to result in a change in one or more dependent variables, also referred to as “output variables” or “response variables.” The experimental design may also identify control variables that must be held constant to prevent external factors from affecting the results.
What is Experimental Design?
Experimental design involves not only the selection of suitable independent, dependent, and control variables, but planning the delivery of the experiment under statistically optimal conditions given the constraints of available resources. There are multiple approaches for determining the set of design points (unique combinations of the settings of the independent variables) to be used in the experiment.
Main concerns in experimental design include the establishment of validity, reliability, and replicability. For example, these concerns can be partially addressed by carefully choosing the independent variable, reducing the risk of measurement error, and ensuring that the documentation of the method is sufficiently detailed. Related concerns include achieving appropriate levels of statistical power and sensitivity.
Need for careful design of experiment arises in all fields of serious scientific, technological, and even social science investigation — computer science, physics, geology, political science, electrical engineering, psychology, business marketing analysis, financial analytics, etc…
Options for open-source DOE builder package in Python?
Unfortunately, majority of the state-of-the-art DOE generators are part of commercial statistical software packages like JMP (SAS) or Minitab. However, a researcher will surely be benefited if there exists an open-source code which presents an intuitive user interface for generating an experimental design plan from a simple list of input variables. There are a couple of DOE builder Python packages but individually they don’t cover all the necessary DOE methods and they lack a simplified user API, where one can just input a CSV file of input variables’ range and get back the DOE matrix in another CSV file.
Features
This set of codes is a collection of functions which wrap around the core packages (mentioned below) and generate design-of-experiment (DOE) matrices for a statistician or engineer from an arbitrary range of input variables.
Limitation of the foundation packages used
Both the core packages, which act as foundations to this repo, are not complete in the sense that they do not cover all the necessary functions to generate DOE table that a design engineer may need while planning an experiment. Also, they offer only low-level APIs in the sense that the standard output from them are normalized numpy arrays. It was felt that users, who may not be comfortable in dealing with Python objects directly, should be able to take advantage of their functionalities through a simplified user interface.
Simplified user interface
User just needs to provide a simple CSV file with a single table of variables and their ranges (2-level i.e. min/max or 3-level). Some of the functions work with 2-level min/max range while some others need 3-level ranges from the user (low-mid-high). Intelligence is built into the code to handle the case if the range input is not appropriate and to generate levels by simple linear interpolation from the given input. The code will generate the DOE as per user’s choice and write the matrix in a CSV file on to the disk. In this way, the only API user is exposed to are input and output CSV files. These files then can be used in any engineering simulator, software, process-control module, or fed into process equipments.
Designs available
- Full factorial,
- 2-level fractional factorial,
- Plackett-Burman,
- Sukharev grid,
- Box-Behnken,
- Box-Wilson (Central-composite) with center-faced option,
- Box-Wilson (Central-composite) with center-inscribed option,
- Box-Wilson (Central-composite) with center-circumscribed option,
- Latin hypercube (simple),
- Latin hypercube (space-filling),
- Random k-means cluster,
- Maximin reconstruction,
- Halton sequence based,
- Uniform random matrix
How to use it?
What supporitng packages are required?
First make sure you have all the necessary packages installed. You can simply run the .bash (Unix/Linux) and .bat (Windows) files provided in the repo, to install those packages from your command line interface. They contain the following commands,
pip install numpy
pip install pandas
pip install matplotlib
pip install pydoe
pip install diversipy
Eratta for using PyDOE
Please note that as installed, PyDOE will throw some error related to type conversion. There are two options
- I have modified the pyDOE code suitably and included a file with re-written functions in the repo. This is the file called by the program while executing, so you should see no error.
- If you encounter any error, you could try to modify the PyDOE code by going to the folder where pyDOE files are copied and copying the two files
doe_factorial.pyanddoe_box_behnken.pysupplied with this repo.
How to run the program?
Note this is just a code repository and not a installer package. For the time being, please clone this repo from GitHub, store all the files in a local directory.
git clone https://github.com/tirthajyoti/Design-of-experiment-Python.git
Then start using the software by simply typing,
python Main.py
After this, a simple menu will be printed on the screen and you will be prompted for a choice of number (a DOE) and name of the input CSV file (containing the names and ranges of your variables).
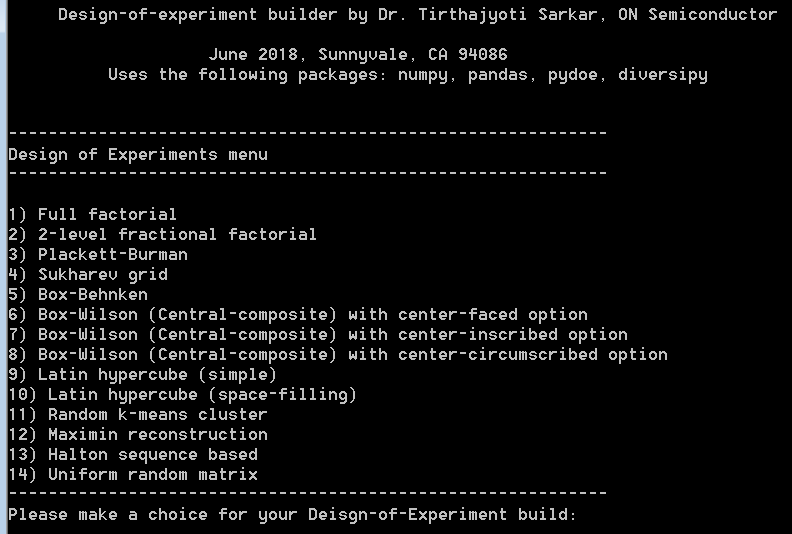
You must have an input parameters CSV file stored in the same directory that you are running this code from. You should use the supplied generic CSV file as an example. Please put the factors in the columns and the levels in the row (not the other way around). Couple of example CSV files are provided in the repo. Feel free to modify them as per your needs.
Is an installer/Python library available?
At this time, No. I plan to work on turning this into a full-fledged Python library which can be installed from PyPi repository by a PIP command. But I cannot promise any timeline for that :-) If somebody wants to collaborate and work on an installer, please feel free to do so.
Examples
Let’s say the input file contains the following table for the parameters range. Imagine this as a generic example of a checmical process in a plant.
| Pressure | Temperature | FlowRate | Time |
|---|---|---|---|
| 40 | 290 | 0.2 | 5 |
| 55 | 320 | 0.3 | 8 |
| 70 | 350 | 0.4 | 11 |
Full-factorial design
If we build a full-factorial DOE out of this, we will get a table with 81 entries because 4 factors permuted in 3 levels result in 3^4=81 combinations!
| Pressure | Temperature | FlowRate | Time |
|---|---|---|---|
| 40 | 290 | 0.2 | 5 |
| 50 | 290 | 0.2 | 5 |
| 70 | 290 | 0.2 | 5 |
| 40 | 320 | 0.2 | 5 |
| 50 | 320 | 0.2 | 5 |
| 70 | 320 | 0.2 | 5 |
| … | … | … | … |
| … | … | … | … |
| 40 | 290 | 0.3 | 8 |
| 50 | 290 | 0.3 | 8 |
| 70 | 290 | 0.3 | 8 |
| 40 | 320 | 0.3 | 8 |
| 50 | 320 | 0.3 | 8 |
| 70 | 320 | 0.3 | 8 |
| … | … | … | … |
| … | … | … | … |
| 40 | 320 | 0.4 | 11 |
| 50 | 320 | 0.4 | 11 |
| 70 | 320 | 0.4 | 11 |
| 40 | 350 | 0.4 | 11 |
| 50 | 350 | 0.4 | 11 |
| 70 | 350 | 0.4 | 11 |
Fractional-factorial design
Clearly the full-factorial designs grows quickly! Engineers and scientists therefore often use half-factorial/fractional-factorial designs where they confound one or more factors with other factors and build a reduced DOE. Let’s say we decide to build a 2-level fractional factorial of this set of variables with the 4th variables as the confounding factor (i.e. not an independent variable but as a function of other variables). If the functional relationship is “A B C BC” i.e. the 4th parameter vary depending only on 2nd and 3rd parameter, the output table could look like,
| Pressure | Temperature | FlowRate | Time |
|---|---|---|---|
| 40 | 290 | 0.2 | 11 |
| 70 | 290 | 0.2 | 11 |
| 40 | 350 | 0.2 | 5 |
| 70 | 350 | 0.2 | 5 |
| 40 | 290 | 0.4 | 5 |
| 70 | 290 | 0.4 | 5 |
| 40 | 350 | 0.4 | 11 |
| 70 | 350 | 0.4 | 11 |
Central-composite design
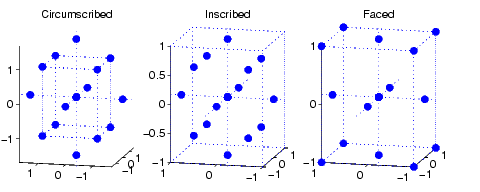
A Box-Wilson Central Composite Design, commonly called ‘a central composite design,’ contains an imbedded factorial or fractional factorial design with center points that is augmented with a group of ‘star points’ that allow estimation of curvature. One central composite design consists of cube points at the corners of a unit cube that is the product of the intervals [-1,1], star points along the axes at or outside the cube, and center points at the origin. Central composite designs are of three types. Circumscribed (CCC) designs are as described above. Inscribed (CCI) designs are as described above, but scaled so the star points take the values -1 and +1, and the cube points lie in the interior of the cube. Faced (CCF) designs have the star points on the faces of the cube. Faced designs have three levels per factor, in contrast with the other types that have five levels per factor. The following figure shows these three types of designs for three factors. [Read this page] (http://blog.minitab.com/blog/understanding-statistics/getting-started-with-factorial-design-of-experiments-doe) for more information about this kind of design philosophy.
Latin Hypercube design

Sometimes, a set of randomized design points within a given range could be attractive for the experimenter to asses the impact of the process variables on the output. Monte Carlo simulations are close example of this approach. However, a Latin Hypercube design is better choice for experimental design rather than building a complete random matrix as it tries to subdivide the sample space in smaller cells and choose only one element out of each subcell. This way, a more ‘uniform spreading’ of the random sample points can be obtained. User can choose the density of sample points. For example, if we choose to generate a Latin Hypercube of 12 experiments from the same input files, that could look like,
| Pressure | Temperature | FlowRate | Time |
|---|---|---|---|
| 63.16 | 313.32 | 0.37 | 10.52 |
| 61.16 | 343.88 | 0.23 | 5.04 |
| 57.83 | 327.46 | 0.35 | 9.47 |
| 68.61 | 309.81 | 0.35 | 8.39 |
| 66.01 | 301.29 | 0.22 | 6.34 |
| 45.76 | 347.97 | 0.27 | 6.94 |
| 40.48 | 320.72 | 0.29 | 9.68 |
| 51.46 | 293.35 | 0.20 | 7.11 |
| 43.63 | 334.92 | 0.30 | 7.66 |
| 47.87 | 339.68 | 0.26 | 8.59 |
| 55.28 | 317.68 | 0.39 | 5.61 |
| 53.99 | 297.07 | 0.32 | 10.43 |
Of course, there is no guarantee that you will get the same matrix if you run this function because this are randomly sampled, but you get the idea!
Acknowledgements and Requirements
The code was written in Python 3.6. It uses following external packages that needs to be installed on your system to use it,
- pydoe: A package designed to help the scientist, engineer, statistician, etc., to construct appropriate experimental designs. Check the docs here.
- diversipy: A collection of algorithms for sampling in hypercubes, selecting diverse subsets, and measuring diversity. Check the docs here.
- numpy
- pandas